

这是一篇记录对于论文Attention is all you need和模型Transformer的解读的文章
原理解读
Why self-attention?
对于输入序列长度为n,每个token的特征表示(embedding)维度为d的情况,Self-Attention层的计算复杂度为O(n^2 d),主要通过计算Self-Attention层的两次矩阵乘法运算得到(Q和K矩阵相乘,K和V矩阵相乘)。尽管表中展示的不同类型的模型计算复杂度相近,但是Self-Attention层相比RNN(Recurrent Neural Network)的序列操作更少,即RNN需要逐token依次进行运算,而Self-Attention对于序列中的token计算可以并行。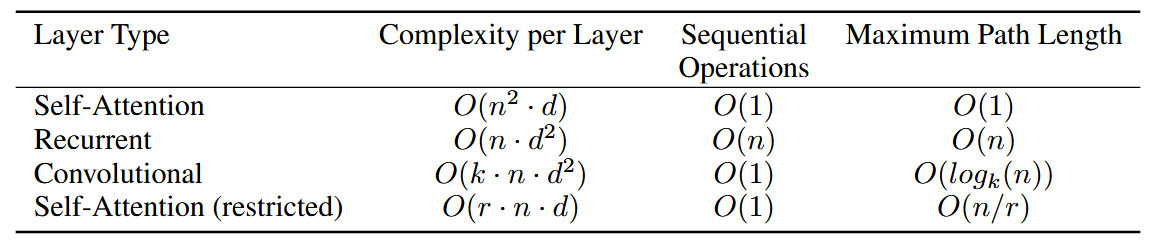
关键技术和模块及其实现
现代神经网络的构建过程比较像搭积木,Transformer也不例外,用一些基本的模块构成网络层,再将网络层连接组成神经网络,本段介绍构成Transformer的这些基本模块和网络层以及它们之间的连接、用到的trick等。
1. Scale Dot Product Attention
2. Multi-head Attention
此处与原文方法略有差异,在Q、K、V的线性变换部分,W^Q、W^K、W^V矩阵不再采用h个\mathbb{R}^{d_{model} \times \frac{d_{model}}{h}}的矩阵再将乘积连接(concatenate)来实现,而是均用1个\mathbb{R}^{d_{model} \times d_{model}}的矩阵实现,两种方法在结果上是等价的。